How Twitch Intelligently Ingests Live Video at Global Scale
by David Zhang, published Feb 13th, 2024
Background Info
Twitch ran into problems when its globally distributed Point of Presence (PoP) server fleet couldn't handle faults or cyclical traffic loads efficiently. This was all due to its stinky HAProxy setup which stupidly sent video data from one PoP to the same origin, regardless of whether or not that origin should or could handle processing. What they did next will shock you!
How Live Streaming Works
Source: ByteByteGo: How Does Live Streaming Platform Work?
Before we can go into Twitch, we first need to take a look at how live video streaming actually works.
Live video streaming is a big pain in the ass because large volumes of video data need to be processed in real time. Video processing (encoding, transcoding) is compute intensive and takes forever.
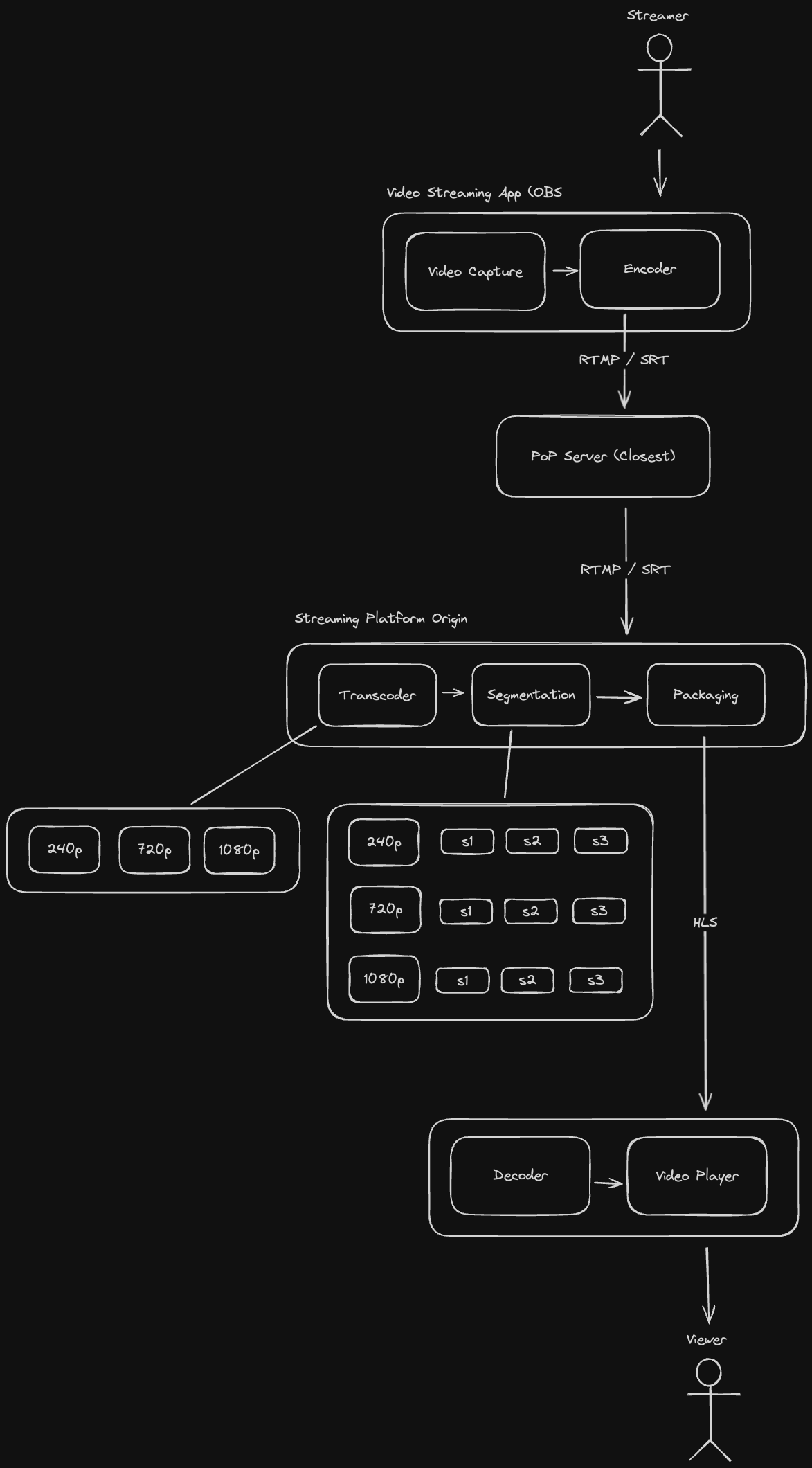
Let's take a look at how video data goes from a streamer to your beady lil' eyeballs:
-
Streamer captures video using software wired to an encoder. (e.g. Open Broadcaster Software (OBS), a browser webcam, or a phone camera)
-
Encoder bundles up the video data and sends it over some transport protocol to the livestream platform (e.g. Twitch, Youtube)
- The most popular transport protocol is RTMP, or Real Time Messaging Protocol. RTMP is a TCP based protocol that was originally built as a live streaming protocol for Adobe Flash. Since Adobe Flash is like a billion years old, RTMP is widely supported.
- Secure Reliable Transport (SRT), is the new kid on the block. Despite being called "reliable", it uses UDP and actually has the hutzpah to guarantee resiliency in the face of shoddy network conditions. (SRT thinks he's HIM)
-
When sending data to the streaming platform, the encoder typically establishes a connection to a Point of Presence (PoP) server.
- Most streaming platforms have a globally distributed fleet of PoP servers.
- The aim of PoP servers is to provide the best possible upload conditions for the streamer, optimizing for low latency via geographical proximity.
-
Once the data reaches a PoP server, it is transported via a fast and reliable backbone network for further processing.
-
This processing involves the following:
- First, the video stream is transcoded into various resolutions and bitrates (e.g. 1080p, 720p, etc.)
- The transcoded video stream is then divided into little pieces that are a few seconds long
- Since transcoding is compute intensive, the different bitrate transcoding piplines execute in parallel
- Then, the transcoded segments are stitched together and transformed into a format that the video players can understand.
- The most common livestreaming format is HLS, or HTTP Live Streaming. This format was invented by Apple in 2009, and sees data arranged into chunks accompanied by a manifest file. Each chunk is a video segment that's a few seconds in length. The manifest file describes the output format of the video chunks as well as where to load them from
- HLS video chunks and manifests are cached by CDNs to improve performance.
-
Finally, the HLS stream data is decoded, decompressed and played by the viewer's video player.
- The video player will automatically switch between various transcoding bitrates based on the quality of the viewer's internet connection. This is known as adaptive bitrate streaming
- Some streaming platforms provide configuration options for streamers to fine tune the quality they want to stream at, thereby providing greater control over latency optimization.
Here's a diagram of what the end to end flow looks like:
Twitch's PoP Problem
Original Twitch Engineering Blog post
Twitch maintains a globally distributed network of PoP servers, which terminate live streams and forward the data to Origin servers for processing (transcoding, etc.).
In the beginning, the setup was pretty simple. They used HAProxy on their PoP servers to just yeet data over to a single origin server. But as they grew, this began to present issues.
Issue #1 - Cyclical, multi-regional load
Load on Twitch is cyclical, and traffic between different regions might have non-overlapping peaks and valleys due to timezone differences. (See diagram below)
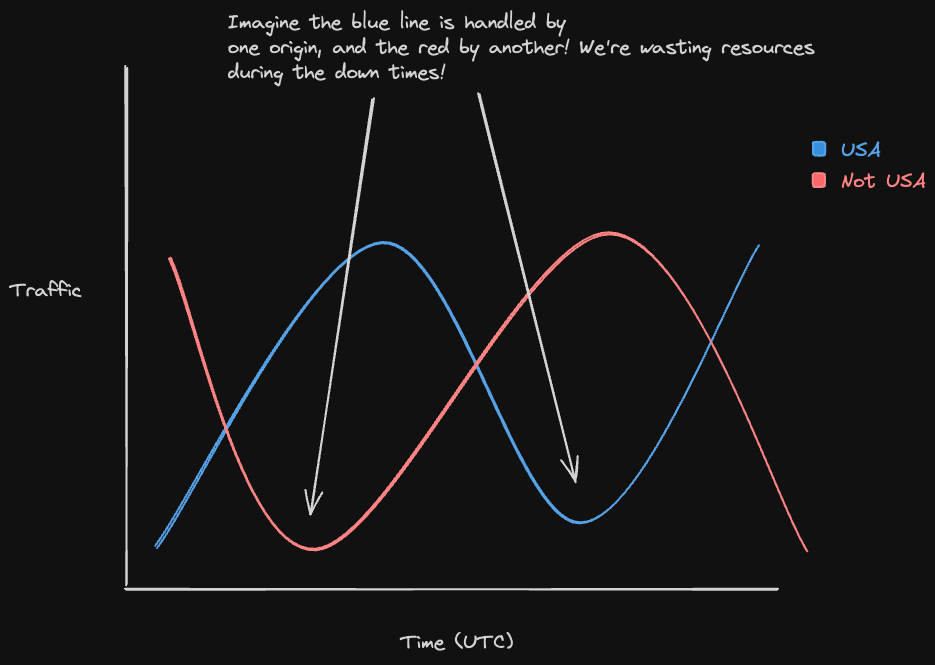
Since each PoP Server could only statically send data over to a single origin, that meant compute and network resources were being underutilized.
Issue #2 - Traffic Surges or Origin Capacity Fluctations
In the event of a super popular stream, PoPs wouldn't be able to dynmically route data to more powerful origins to handle the burst traffic. On the flip side, if an origin loses capacity due to random system fluctuations, PoPs can't really react either. This is all due to origin destinations being statically defined in HAProxy.
Issue #3 - Fault Tolerance
If an origin goes down, the PoP is SOL (Shit outta luck). Once again, HAProxy is the culprit here - the static origin definitions hamstring PoP's ability fo failover in the event that an origin dies.
Issue #4 - Future Stuff
PoPs will need to run custom software in the future that can support multiple media transport protocols (SRT, perhaps?)
Enter Intelligest
Twitch developed Intelligest, a proprietary ingest routing system to intelligently distribute video traffic from PoPs to origins.
Intelligest has two components:
-
Intelligest Media Proxy - the new proxy that runs in the PoPs, which terminates live video streams from broadcasters, extracts relevant properties of the streams, and uses Intelligest Routing Service to determine which origin to send data to. It supports a variety of different transport protocols.
-
Intelligest Routing Service (IRS). The routing service responsible for making routing decisions for live video streams. It's a stateful service that can be configured to support rule-based routing for different use cases. (e.g., always sending data from certain streams to a particular origin due to special processing needs)
Twitch's Big Brain Routing Optimization
Twitch also did a very interesting, smartypants thing to optimize their IRS routing configurations. They looked at their historical ingest traffic data, network topology, and available origin compute resources and constructed an optimization problem to determine how much traffic should be sent to each origin.
They then fed this problem into an optimization solver and pre-computed a routing configuration for IRS offline! This resulted in much more efficient usage of network resources.
Of course, the main limitation of this is that the problem is solved offline, so it can't really adapt to sudden fluctuations in traffic or capacity and has to be recomputed from time to time.
Or can it? 🤔 VSauce Theme starts playing
Dynamic Routing Computation
Yes, that's right. You have been #jebaited. Twitch actually developed not one, but TWO subsystems that can track compute and network utilization across the Twitch Platform in real time, specifically to optimize route configurations on the fly. They're called Capacitor and The Well respectively, which sound like A24 movie titles.
Anyways, Capacitor monitors available compute resources, and The Well monitors the network. IRS uses both data sources to construct a real time view of the Twitch video processing infrastructure. It then uses a randomized greedy algorithm to dynamically compute routing decisions. (Jumpin Jehosaphat! It's been a hot minute since I've heard the term greedy algorithm 🤓🤓)
Twitch is now much more fault tolerant, able to dynamically re-route traffic in the event of origin failures. Losses in compute resources or network outages are immediately reflected in Capacitor and The Well. They're even able to deal with wider scale failures like regional control plane outages.
The Takeaway
So yeah, in short, if you're ever trying to intelligently route live video data for efficient compute utilization, maybe you 🫵 should try building four new pieces of software to orchestrate the process. Also maybe dust off those advanced algo textbooks from college.